All Stories


![[RDBMS] 정규화&역정규화](/assets/images/rdbms.png)

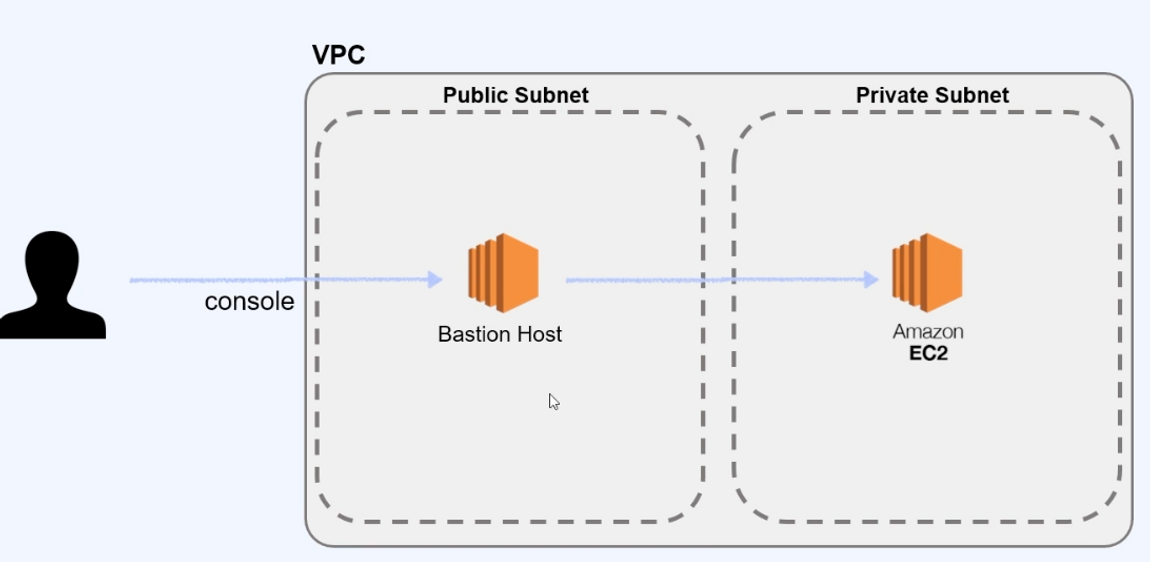
AWS Private subnet (VPC, NAT gateway, Bastion)
오늘은 NAT Gateway, Bastion이 필요한 상황을 알아보고 AWS 네크워크 환경을 구성해볼 예정입니다.
Jr Data Engineer
