About Me
B2C 중심의 테이블오더·결제·데이팅 서비스 영역에서 3년간, 대규모 로그 및 트랜잭션 데이터 파이프라인을 구축하고 최적화했습니다.
데이터의 규모와 리소스를 고려해, 상황에 맞는 합리적인 인프라를 설계하는 데이터 엔지니어입니다.
AWS와 Kubernetes 기반 클라우드 환경 위에, 실시간 로그 수집부터 Lakehouse 기반의 분석 마트까지 직접 설계하고 운영해왔습니다.
Airflow, Python, Spark, IaC, CI/CD를 활용해 자동화된 데이터 워크플로우를 구현하며, 효율성과 재현성을 함께 고민합니다.
데이터는 곧 비즈니스 방향성을 검증하는 출발점이라는 신념을 가지고 일합니다.
마케터, 기획자, 데이터 분석가와의 협업을 통해 로그 택사노미, 유저 행동 분석, 마케팅 성과 분석 등을 실현해왔습니다.
로그 스키마 표준화와 데이터 거버넌스 체계 구축에도 깊이 관여했습니다.
데이터로 말하고, 문제를 구조화하며, 팀과 함께 성장하는 방향을 추구합니다.
지속적인 학습과 실전 경험을 통해, 더 나은 데이터 엔지니어가 되기 위해 노력하고 있습니다.
최종 목표는 람다 아키텍처에서 카파 아키텍처로 유저에게 제가 만든 데이터를 경험하게 하고 싶습니다.
Work Experience
테이블 오더 1위
티오더
https://www.torder.com/
Data Egineer
2024.01 - 현재
- 서비스, 로그 데이터 수집 파이프라인 구성
- 대용량 데이터 처리 환경 구성
- 데이터 분석 환경 구축
- DataLakeHouse, DataMart 구축
- Medallion 아키텍처 설계 구성
- CI/CD 배포 자동화
- 로그 텍사노미 스키마 설계
- 전사 대시보드 구성
- 이슈 탐지 모니터링 및 알람 시스템 구성
프리미엄 만남 보장 데이팅 서비스
Wclub, Baro
https://wclub.co.kr/
Data Egineer
(퇴사 사유 : 급여 미지급)
2022.10 - 2024.01
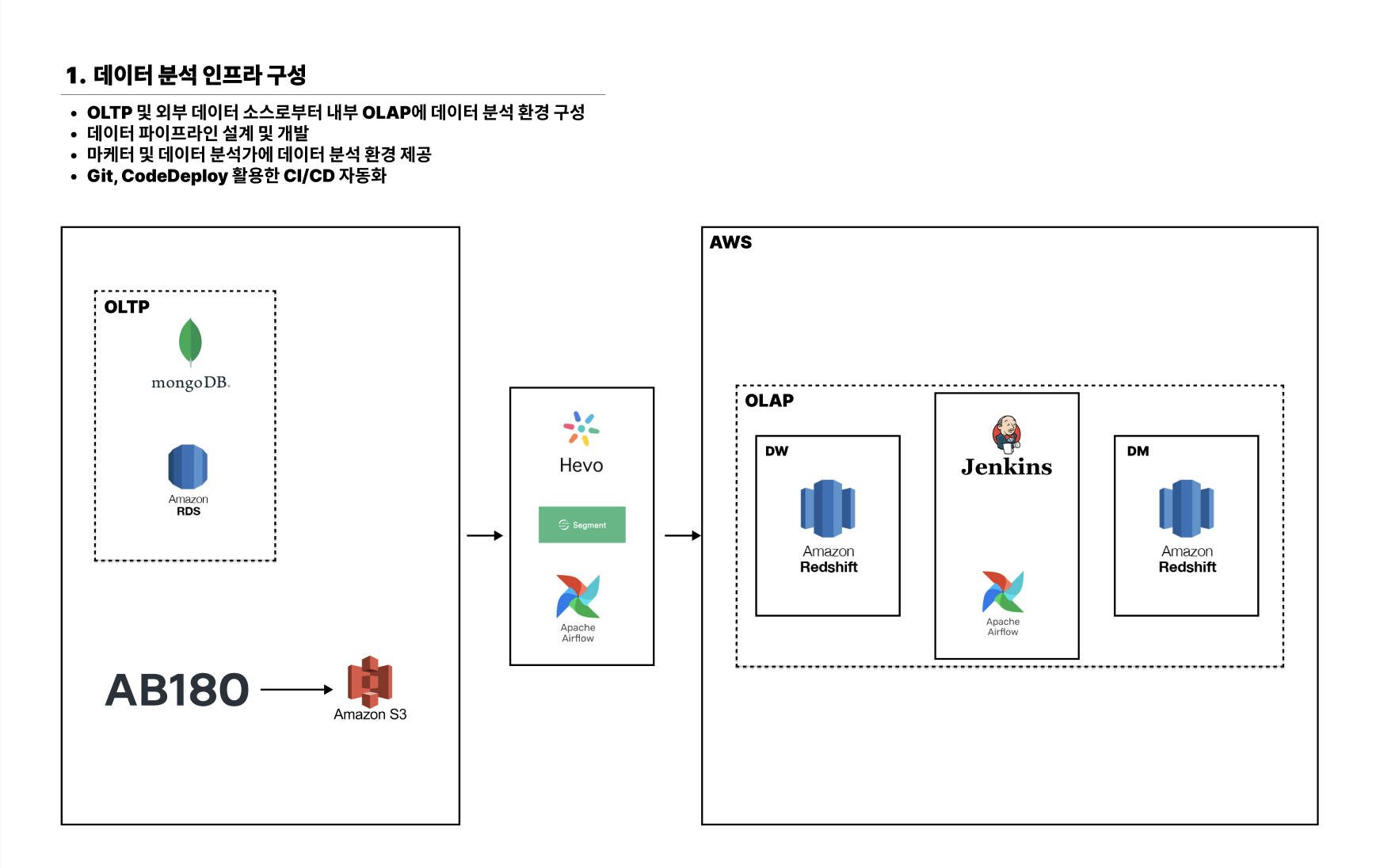
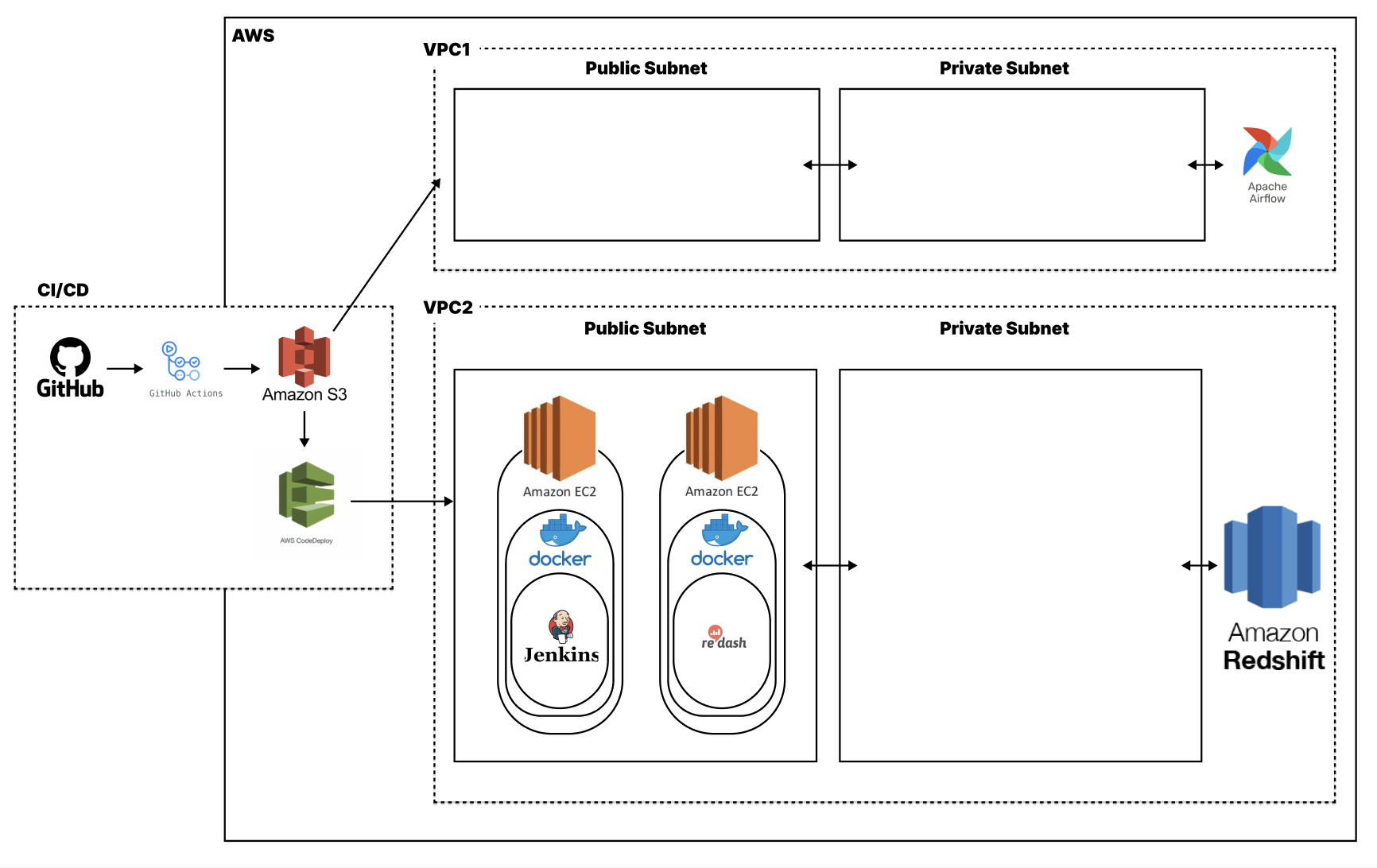
- 데이터 분석 인프라 구성
- 마케팅 효율 분석 지원
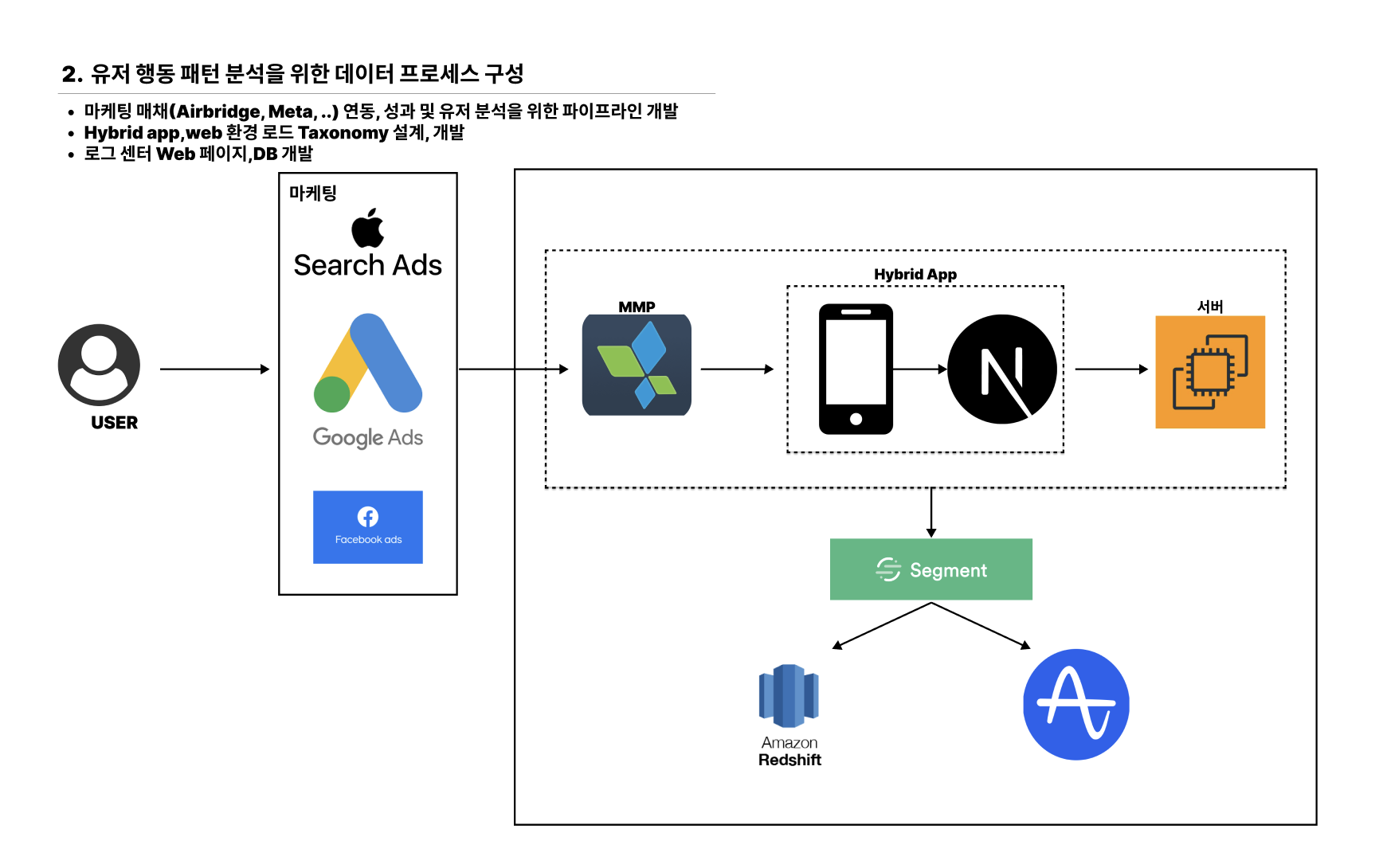
- 유저 행동 패턴 분석을 위한 데이터 프로세스 구성
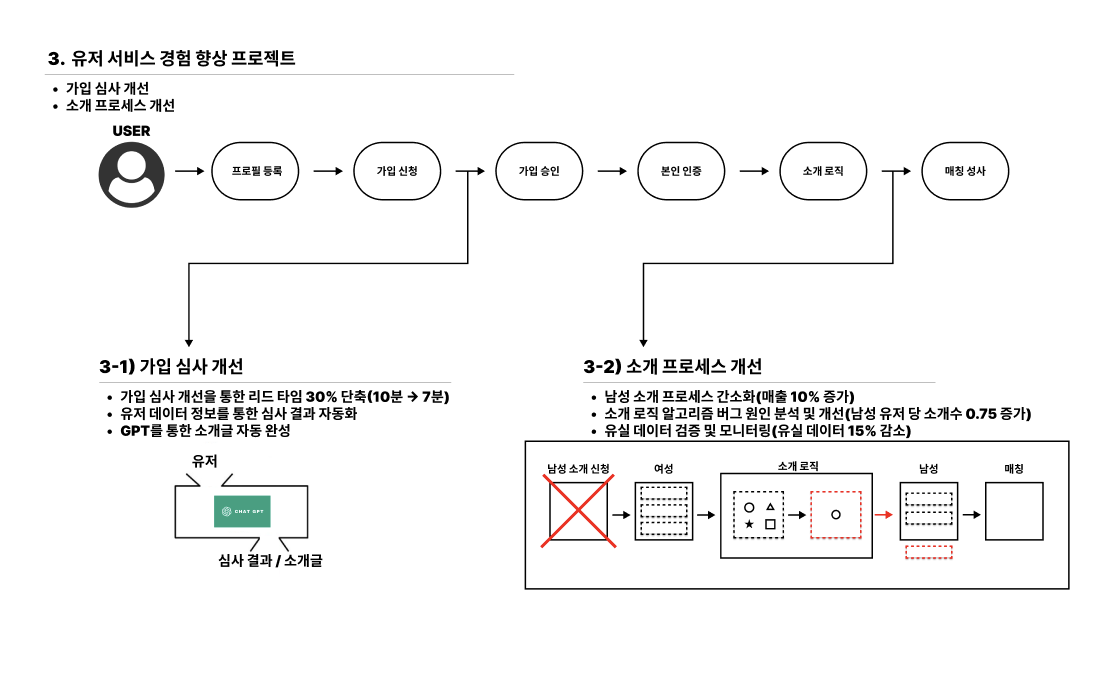
- 가입 심사 개선
- 소개 프로세스 개선
일 50만건, 12만개 가맹점 모바일 결제 PG기기 결제 서비스 스타트업
다날
https://www.danalpay.com/
Data Developer
(퇴사 사유 : 데이터 엔지니어 진로 확정)
2021.02 - 2022.04
- 결제 서비스 DB개발 및 운영
- 전자계약, 파트너센터 DB 개발 및 운영
- 사내 백오피스 DB 개발
- 2021 상반기 우수사원 수상
Skills
현재 업무에 사용 혹은 사용했던 기술들입니다.
Cloud & Infra
- Kinesis
- Firehose
- Lambda
- ECR
- Athena
- Glue
- S3
- ElasticCache
- Apigateway
Data Storage & Query Engine
- AWS RDS(Mysql, Aurora, Postgresql)
- Athena
- Iceberg
- Mssql
- Mongodb
- AWS Redshift
Programming & Container
- Python
- PySpark
- Shell Script
WorkFlow & Monitoring
- Kinesis
- Airflow
- Jenkins
- Cloudwatch
- SNS
- Chatbot
DevOps
- Kubernetes
- Docker
- ArgoCD
- Git Actions
- Terraform
- Codedeploy