Category Spark
Spark Memory 구조에 대해 알아보겠습니다.
Spark는 흔히 Map-Reduce를 Memory에 올리는 장점으로 Hadoop → Spark로 변화해왔다.
가상 로그 데이터를 Streaming 처리해보기라는 목표를 가지고 지금까지 어떻게 구성했는지를 소개드리려고 합니다.
지금까지, 로그 데이터 구성하기를 진행하는 과정에 있어 Kafka, HDFS, Spark 클러스터를 구성하였습니다.
Pyspark로 연결 시도 시 datanode에 값이 없다고 한다.
Aws Instance로 Kafka클러스터를 구성한 뒤, Docker 위에 Spark를 구성하여 Hadoop으로 전송하려고 합니다.
RDD에 이어 더 간편하게 사용가능한 Sparksession의 Dataframe 기능을 사용해보려고 합니다.
Spark 기본 연동도 마쳤으니 RDD와 Dataframe을 상세히 써보려고 합니다.
Python의 도움을 받아 RDS를 연결하여 Spark를 활용한 전처리를 시도 중. Node -> EC2 -> AWS RDS Mysql에 있는 데이터를 가져오는 것이 목표. ssh를 통한 연결까지는 성공하였으나, 이후에 jdbc로 부르는 부분이...
AWS RDS Mysql과 Spark를 연결하는 과정에서 많은 애로사항을 겪었고 이를 간략하게 정리하여 봅니다.
Docker를 활용하여 Local에 구성하며 테스트하려는 목적에 따라 구성하였습니다.
Spark Architecture에 대해 알아보겠습니다.
Docker
Spark 설치하여 Zeppelin 실행까지
Category dataengineer
Category AWS
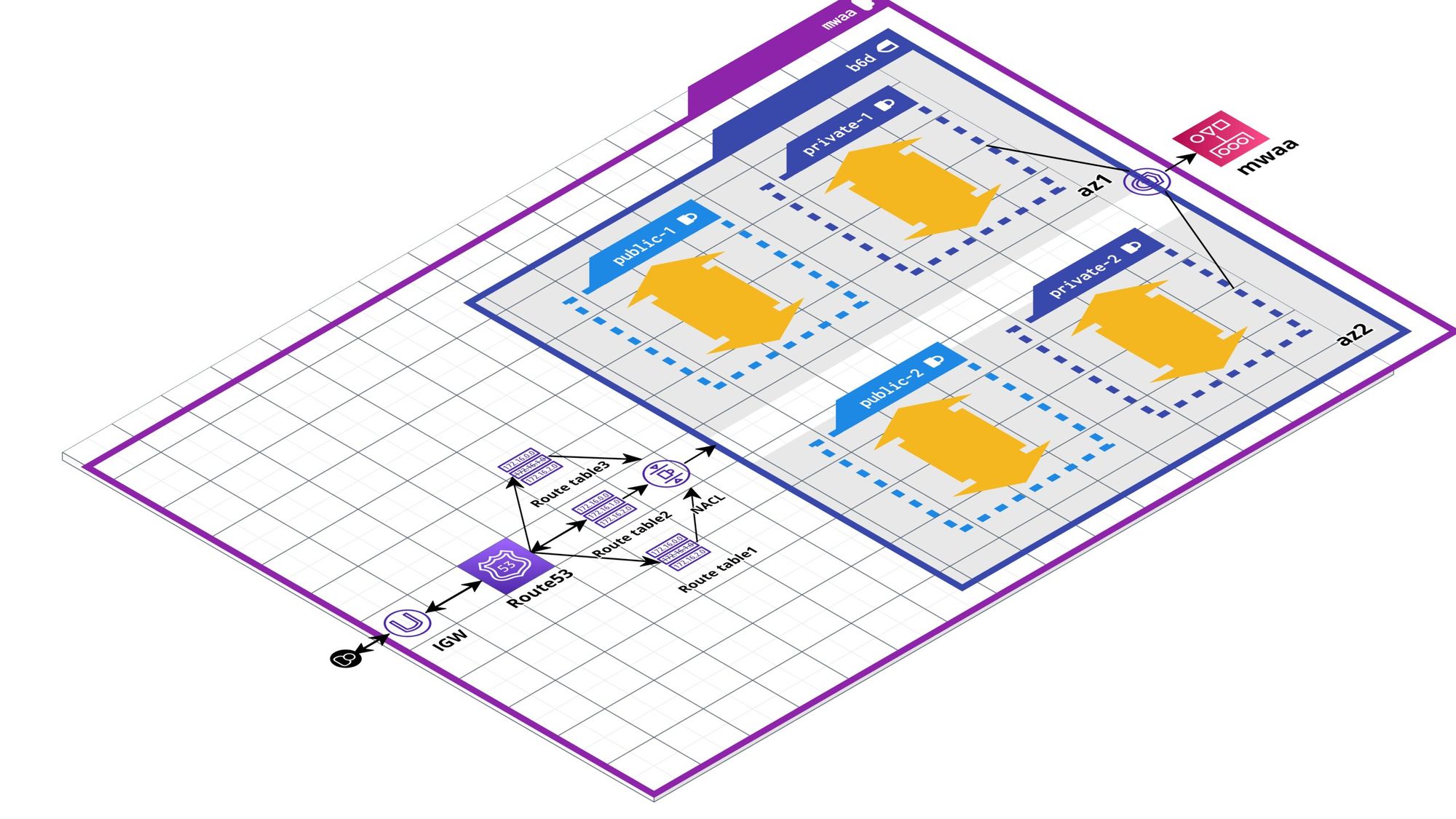
오늘은 NAT Gateway, Bastion이 필요한 상황을 알아보고 AWS 네크워크 환경을 구성해볼 예정입니다.
가상의 대용량의 로그 데이터를 만들어 Kafka → Hadoop에 저장해보려고 합니다.
오늘은 SSH 연결 방식을 바꾸어 보려고 합니다.
Python의 도움을 받아 RDS를 연결하여 Spark를 활용한 전처리를 시도 중. Node -> EC2 -> AWS RDS Mysql에 있는 데이터를 가져오는 것이 목표. ssh를 통한 연결까지는 성공하였으나, 이후에 jdbc로 부르는 부분이...
AWS RDS Mysql과 Spark를 연결하는 과정에서 많은 애로사항을 겪었고 이를 간략하게 정리하여 봅니다.
EC2 Instance를 구성하면서 매번 처음부터 세팅하고 번거로움을 줄이기 위하여 사용
AWS 계정 추가
AWS → IAM → Create User를 선택하여 줍니다.
Are you providing to the aws management console → IAM User
AWS EC2 CI/CD 환경 구성 관련하여 애기하려고 합니다.
Datagrip을 통하여 여러 Database 환경을 빠르고 쉽게 접근하기 위한 세팅 방법입니다.
안녕하세요
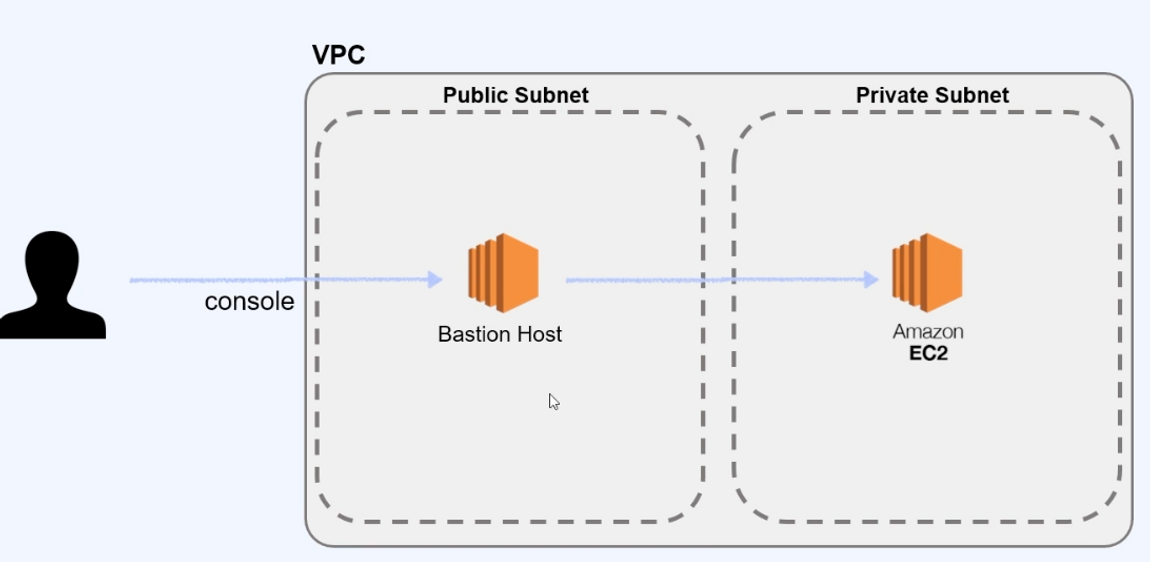
오늘은 AWS EC2 Service에 접근하기 위한 방법을 알려드리려고 합니다.
일반적으로 EC2 Service는 Private Subnet에 구성되어, 외부에서 접근이 불가능합니다.
안녕하세요
오늘은 AWS Network를 구성하면서 모르는 부분이나 상세히 이해가 안간 부분에 다시 알아보려고 합니다.
Category IAM
Category Network
AWS에서 Inbound를 설정하다보면 하다보면 0.0.0.0/0과 ::/0 연결하는 방식이 다르다.
안녕하세요
오늘은 AWS Network를 구성하면서 모르는 부분이나 상세히 이해가 안간 부분에 다시 알아보려고 합니다.
Category Airflow
Airflow를 다른 Executor를 활용해서 구성해보고 실행해보려고 합니다.
Componenets Webserver : Flask Server Scheduler : Daemon Metastore : database where metadata are stored Executor : class defining How your tasks should be executed Worker : process/subprocess executing task...
Catchup
True : Start_date부터 현재시점까지의 모든 스케줄링을 모두 실행
False : Start_date가 아닌 현재 기준으로부터 모든 스케줄링 실행
이 때, 모든 Task가 동시에 실행될 수 있으니, 주의 필요
Airflow
N 배치인 경우 N전 기준으로 돈다고 이해하면 된다.
SparkOperator
1
$ pip install pyspark
Python Operator
💡 Python 코드를 실행하는 Operator
Airflow에서는 하나의 Workflow를 DAG로 구성한다.
Dummy Operator
💡 아무 작업을 하지 않는 Operator
Bash Operator
💡 Bash shell script를 실행하는 Operator
Task 의존성이란?
Linear chain dependency
>> 연산자를 사용하여 의존성
오늘은 Airflow 기본 필수 개념인 스케줄링과 멱등성,원자성에 대해 알아보려고 합니다.
안녕하세요
오늘은 Airflow Dag 구조에 대해 설명하려고 합니다.
안녕하세요
오늘은 Mongodb와 연동하여 데이터 가져오는 파이프라인 구축 관련해서 이야기 해보려고 합니다.
안녕하세요
오늘은 S3 Parquet 데이터를 Redshift에 적재하는 방법에 대해 공유드리려고 합니다.
안녕하세요
오늘은 Airflow External 개념에 대해 알아보겠습니다.
안녕하세요 오늘은 Airflow 스케줄링하며, 특정 주기 동안 조건을 만족했을 때 진행하도록 하기 위함 데이터 마트 구축 시 Collection 별로 스케줄링 하는 것이 아닌 순차적으로 진행시키게 하도록 할 때(메모리 이슈로 분할...
안녕하세요
오늘은 Airflow를 다루며, 필요?사용하였던 개념들에 대해서 다시 작성해보았습니다.
Category Linux
Dockerfile 설정
Docker가 미리 설치되어있다는 가정하에 진행합니다.
여러 테스트 환경을 구축할 때 사용합니다.
sudo command 까지 설치하여 줍니다,.
uninstall
1
$ for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do sudo apt-get remove $pkg; done
리눅스 사용하면서 썻던 명령어들을 정리하여두었습니다.
Category Code
Category OS
안녕하세요
오늘은 OS Process에 대해 다시 개념을 적립해보려고 합니다.
Category Python
요구 사항
만약, 내부 서비스에 대해 누가 사용한지 여부를 로깅하여 컨트롤하고 싶다면 어떻게 해야 할까?
앞에서는 가상의 로그 데이터를 발생시켰습니다.
로그 데이터 전체적으로 구성하기 위해서는 로그 데이터가 필요합니다.
Python 코드의 기술 책을 읽으면, Python 답게 코드를 작성하는 방법을 작성합니다.
문자열 시퀀스 데이터는 2가지 유형으로 나누어집니다.
혼공파 책을 통하여 Python 다시 한번 기초 정리를 해보았습니다.
상세한 내용은 넘어갔습니다.
Python에서 병렬처리를 하기 위함
쏘카와 AWS Glue에서도 점점 Python Ray 병렬처리 용도로 많이 하여 어떤것인지 궁금하여 조사해보았습니다.
파이썬 멀티 프로세싱 동작 원리와 어떤 상황에서 사용하는 것인지 적합한지를 직접 확인해보려고 합니다.
상황에 따라 Config 파일을 별도로 만들어두어 관리하는 것이 편리하다.
loads()
Json 문자열 → Python Object
Iterable
반복 가능한 Object
한번 iterate 할 수 있다.
iter = method에 의해 iterator Object로 변경된다.
list, dict, set, str, bytes, tuple, range
회사에서 Dashboard를 요청하게 되어 고민하던 도중 아래와 같이 많은 대시보드 library를 검색하게 되었다. 전사 직원 누구나 어디서든 손쉽게 접근이 가능할 수 있도록이라는 목적에 맞추어 웹 배포가 가능한 Streamlit을 활용하여 구성하도록...
Self
self = class intance를 나타나는데 사용
method = Class의 function
class 내의 method들은 self라는 parameter 값을 가지게 된다.
Lambda function runtime에 생성해서 사용 할 수 있는 익명 함수 익명 함수 = 함수명을 명명하지 않고 사용가능한 함수 필요한 곳에서 즉시 사용 후 버릴 수 있어 코드가 간결 + 메모리...
Python은 OOP 객체지향 언어입니다.
Class를 지원하면 Object 형태를 나타낼 수 있습니다.
Python에서 List와 Array를 어떻게 구별하여 쓰는지 알아보겠습니다.
Case-sensitive란?
대소문자를 구별하여 인식하는 경우
Python은 일반 프로그래밍 언어와 동일하게 대소문자를 구별한다. (java,c++,js)
동일한 이름의 변수이더라도 결과는 다르다.
pathlib
Object-oriented filesystem paths
Module import- 모듈을 임포트 할 수 있는 방법 ( 참고 ) __name__ - entry point of module entry point - file 실행 시작 파일 pip list pip show library 모듈...
오늘은 Python 가상 환경을 만들었습니다.
저는 AWS와 동일한 환경을 구성하여 개발 코드 테스트로 사용 중에 있습니다.
Namespace란? 특정한 Object를 이름에 따라 구분할 수 있는 범위 Python은 모든 것들을 Object로 관리한다고 말씀드렸는데, 특정 이름과 Object를 Mapping 관계를 Dictionary 형태로 가지고 있다. 각 Namespace는 딕셔너리 형태로 구현되며, Namespace의...
안녕하세요
오늘은 Python 기본 코드 가이드라인으로 유명한 PEP8에 대해서 알고 있는 바를 공유 드리려고 합니다.
안녕하세요
오늘은 Python이 메모리를 어떻게 관리하는지에 대해 알아보겠습니다.
평상시에 Python 언어로 코드를 자주 작성하는데 데이터를 어떻게 처리하고 메모리에 어떤 방식으로 올라가는지 궁금하여 작성합니다.
Python은 어떤 유형의 언어인가?
객체 지향형 스크립트 언어이다.
인터프리터에서 컴파일 없이 한줄씩 읽어서 실행 가능하다.
What is the difference between list and tuples in Python?
정답
값이 변경 가능한가? 여부
메모리 → 속도 차이
What are the key features of Python? 배우고 읽기 쉽다. 키워드,구조,명확하게 정의 된 구문. 인터프리터 언어 인터프리터에 의해 실행 시 처리 → 컴파일 필요X 동적 타입 언어 동적 데이터 유형,...
Category S3
안녕하세요
오늘은 S3 Parquet 데이터를 Redshift에 적재하는 방법에 대해 공유드리려고 합니다.
Category Redshift
Redshift Copy 명령어를 통해 S3 파일 정보 업로드하기
Jenkins-Redshift에서 연결
결과 - Private Ip Inbound 세팅
Redshift Architecture Wclub 1Leader Node 3Compute Node Cluster Database Slice 각각 메모리, Disk, Cpu 할당 독립적인 워크로드로 병렬 실행 Leader Node query 실행 및 데이터 분산 처리 담당 Client와 Communicate...
안녕하세요
오늘은 S3 Parquet 데이터를 Redshift에 적재하는 방법에 대해 공유드리려고 합니다.
Category Mongodb
안녕하세요
오늘은 Mongodb와 연동하여 데이터 가져오는 파이프라인 구축 관련해서 이야기 해보려고 합니다.
Category AwS
Redshift Architecture Wclub 1Leader Node 3Compute Node Cluster Database Slice 각각 메모리, Disk, Cpu 할당 독립적인 워크로드로 병렬 실행 Leader Node query 실행 및 데이터 분산 처리 담당 Client와 Communicate...
Category SSH
오늘은 SSH 연결 방식을 바꾸어 보려고 합니다.
안녕하세요.
오늘은 SSH에 대해서 알아보겠습니다.
또한, Ubuntu 버전을 올리며 SSH 버전이 올라가 생긴 이슈 처리에 대해 공유드리려고 합니다.
Category Mssql
안녕하세요 오늘은 예전 회사에서 재직중에 있었던 서버 부하 이슈 처리를 공유드리려고 합니다. 그 때 당시 대부분의 시니어분들이 퇴사하였고 팀 내에 혼자 결제 데이터를 개발,운영하고 있었습니다. 아래와 같은 문제가 발생하였으며 이슈에...
Category Streamlit
회사에서 Dashboard를 요청하게 되어 고민하던 도중 아래와 같이 많은 대시보드 library를 검색하게 되었다. 전사 직원 누구나 어디서든 손쉽게 접근이 가능할 수 있도록이라는 목적에 맞추어 웹 배포가 가능한 Streamlit을 활용하여 구성하도록...
Category Distributed System
분산처리 시스템에서의 동시성과 단일 노드에서 동시성을 제어하기 위한 Lock들을 소개하고 어떤 점이 다른지 소개 드리려고 합니다. Mutex 특정 쓰레드, 프로세스가 공유 Resource에 접근하는 것을 동기화 하는데 사용. 하나의 쓰레드가 Mutex...
앞에서 공유드린, BASE, CAP를 알고 있다는 가정하에 추가적으로 설명합니다.
분산처리에 들어가기 앞서, 기본 특성을 살펴봅니다.
Category Nosql
Nosql 특징 유연한 스키마 - 데이터 구조가 자주 변경될 것으로 예상 Read,Write 속도가 빠르다. 다양한 데이터 모델 - Key,value / 문서 / 칼럼 패밀리/ 그래픽 Database 지원 복제와 분할 허용...
Category File
Parquet Column Base 저장 공간 효율(데이터 압축) I/O 작업 최소화 병렬 처리, Vector화 WORM = Write Once Read Many 복잡한 중첩 데이터 구조 지원 1 2 3 4 5 6...
Category EC2
Jenkins-Redshift에서 연결
결과 - Private Ip Inbound 세팅
EC2 Instance를 구성하면서 매번 처음부터 세팅하고 번거로움을 줄이기 위하여 사용
AWS EC2 CI/CD 환경 구성 관련하여 애기하려고 합니다.
EC2 Instance 띄운 후 SSH Connection 연결 처리하였으나, Web으로 접근 시에 제대로 연결이 되었는지 알기 위하여 정리한 내용입니다.
EC2 Instance를 띄운 후에 Command를 통하여 SSH로 연결하는 방식을 알아보겠습니다.
Category Datagrip
Datagrip을 통하여 여러 Database 환경을 빠르고 쉽게 접근하기 위한 세팅 방법입니다.
Category Jenkins
요청 사항
매 시간 마다 구글 시트에 사내 지표를 상세히 알고 싶다.
빠른 작업을 위해 Jenkins에 구성
Jenkins-Redshift에서 연결
결과 - Private Ip Inbound 세팅
Category CI/CD
AWS EC2 CI/CD 환경 구성 관련하여 애기하려고 합니다.
Category Docker
Dockerfile에서 CMD와 ENDPOINT의 차이를 알아본다.
Dockerfile 구성 시 사용 할 수 있는 명령어를 정리해두었습니다.
Docker를 사용하면서 사용했거나 필요하다고 생각되는 명령어 위주로 정리히보았습니다.
중간에 과제 혹은 코딩테스트를 진행하면서 글을 많이 쓰지 못하였다. 과제를 거치며, 이 부분은 어떻게 하는지 궁금하여 글을 씁니다. Docker를 구성하는 과정에서 내부 컨테이너끼리는 통신하는 글을 엄청 많으나, 외부에서 서비스를 접속하는...
docker ps vs docker ps -a
docker ps = 현재 실행 중인 컨테이너 목록
docker ps -a = 현재 실행 중인 컨테이너 + 멈춘 컨테이너
Category RDS
앞에서 배운 mysql dump를 활용하여 실제 운영되는 서비스 데이터를 Dev 환경에 가져오려고 합니다.
Enable Mysql Query Log
https://stackoverflow.com/questions/6479107/how-to-enable-mysql-query-log
Python의 도움을 받아 RDS를 연결하여 Spark를 활용한 전처리를 시도 중. Node -> EC2 -> AWS RDS Mysql에 있는 데이터를 가져오는 것이 목표. ssh를 통한 연결까지는 성공하였으나, 이후에 jdbc로 부르는 부분이...
AWS RDS Mysql과 Spark를 연결하는 과정에서 많은 애로사항을 겪었고 이를 간략하게 정리하여 봅니다.
Production Data와 Dev Data의 Sync를 종종 맞추어 개발하고 싶다고 하여 개발한 과정입니다.
Category Hadoop
가상 로그 데이터를 Streaming 처리해보기라는 목표를 가지고 지금까지 어떻게 구성했는지를 소개드리려고 합니다.
지금까지, 로그 데이터 구성하기를 진행하는 과정에 있어 Kafka, HDFS, Spark 클러스터를 구성하였습니다.
Pyspark로 연결 시도 시 datanode에 값이 없다고 한다.
Client가 Data를 저장할 때 여러 곳에 분산처리하여 저장한다.
이 때 Rack이 장애가 날 수 있으니, 이를 방지하기 위함 + Failure Tolerance
Client가 HDFS에 Read하고 Write하는 과정
HDFS
Hadoop은 분산 파일 시스템으로 구성(Fault-toerlant 방지)
Master/Slave Architecture로 구성
데이터 block은 3개의 replicas data block응로 나누어지며, rack의 여러 노드에 저장된다.
Category K8S
kubernetes Airflow 구성 중에 helm을 통해 upgrade하는 과정에서 나타난 오류 해결 과정에 대해 설명하려고 합니다.
오늘은 Airflow에 원하는 Library를 Requirement로 Image화 시켜 적용 시키는 과정을 공유드리려고 합니다.
생각보다 구성하는데 오래 걸렸습니다. ㅠㅠ ( 야근과 에러의 연속으로 인하여 )
Kubernetes Cluster = docker에 1master-3worker로 구성
Job
일회성으로 실행되는 서비스
특정 동작을 수행 뒤 종료
Pod는 Completed가 최종 상태
앞에서 경험한 configmap을 통하여 환경변수를 동기화 시켜 사용이 가능하다.
Namespace
컨테이너를 논리적인 영역으로 나누는 역할
Database의 Schema와 같은 개념
CPU, Resource 할당을 제한 할 수 있다.
configmap
Config 값에 대해 미리 지정 후 Pod 배포 시 실행
아래 2가지의 yml 파일로 구성
configmap.yml
deployment.yml
아래 그림과 같이 metallb를 설치하기 전 상태부터 확인하여 봅니다.
service의 기본 개념이 LoadBalancer 배포 방법을 알아보려고 합니다.
Kubernetes에서 기본이 되는 Object에 대해 알아보려고 합니다.
Kubernetes로 Grafana 구성을 해본다.
K8S의 기본 Namespace = kube-system MSA 구조로 동작한다. 가장 기본이 되는 구조로써, default Namespace에 남아있지 않는다. Master = API Server + etcd(database) + Scheduler + Worker = Kubelet 1 2...
kubectl
kubectl 명령어를 통하여 kubernetes control를 한다.
kuberenetes의 상태를 확인하고 원하는 상태를 요청
Kubernetes Cluster란?
K8S를 배포하면, K8S Cluster를 실행하고 있다고 생각하면 된다.
Master Node + Worker Node로 구성
일반적으로 많은 강의에서도 볼수 있듯이 K8S를 사용하기 위해서는 Virtual Box를 사용하여 구축한다.
Category sql
1204. Last Person to Fit in the Bus
1193. Monthly Transactions I
1174. Immediate Food Delivery II
1164. Product Price at a Given Date
문제
배우와 감독이 최소 3회 이상 같은 업무를 한 경우
문제
고객, 상품 테이블이 존재한다.
상품 테이블에 모든 상품을 구매한 고객을 추출하라
문제
성별 칼럼 반대로 업데이트 하라
update 문은 단일로 수행
select 절을 활용하면 안된다.
문제
두 id가 연속되어 있는 경우에, 위치를 바꾸어서 출력
다만, 마지막 혼자 남는 경우에는 그대로 이름을 나둔다.
문제
영화 관련한 별점 테이블이 존재
지루하지 않고 홀수인 id에 대해 평점 높은순으로 출력
문제
숫자가 중복되지 않은 수 중 가장 큰 값
없는 경우는 NULL
문제
삼각형 여부를 판단한 결과를 같이 나타내라
문제
각 노드 별 Parent 정보가 주어진다.
각 Node가 Root, Leaf, Inner인지 구별하여 출력
순서는 상관 없다.
문제
SalesPerson, Company, Orders 3개의 테이블이 존재한다.
각각의 테이블은 Orders와 엮여있다.
RED 회사와는 연관이 없는 salesperson 이름 전체를 조회하라
문제 링크 - https://leetcode.com/problems/friend-requests-ii-who-has-the-most-friends/
문제 링크 - https://leetcode.com/problems/human-traffic-of-stadium/
링크 - https://leetcode.com/problems/classes-more-than-5-students/
문제
area와 population 값이 요청한 값 보다 더 큰 이름만 출력
링크 - https://leetcode.com/problems/investments-in-2016/description
문제
참조 id가 2가 아닌 모든 사람을 구하라
문제
보너스 수령이 1000 아래인 직원들을 출력
196. Delete Duplicate Emails
185. Department Top Three Salaries
184. Department Highest Salary
** 180.Consecutive Numbers**
176. Second Highest Salary
Category redshift
Category hadoop
Hadoop 클러스터를 EC2를 활용하여 구성 중에 있습니다.
EC2를 활용하여 Hadoop Cluster를 구성 과정을 보여드리려고 합니다.
EC2에 가상 분산 모드를 구성해보려고 합니다.
Category Pytest
Category MultiProcessing
Python에서 병렬처리를 하기 위함
쏘카와 AWS Glue에서도 점점 Python Ray 병렬처리 용도로 많이 하여 어떤것인지 궁금하여 조사해보았습니다.
파이썬 멀티 프로세싱 동작 원리와 어떤 상황에서 사용하는 것인지 적합한지를 직접 확인해보려고 합니다.
Category PEP8
Python 코드의 기술 책을 읽으면, Python 답게 코드를 작성하는 방법을 작성합니다.
Category python_leetcode
5. Longest Palindromic Substring
4. Median of Two Sorted Arrays
3. Longest Substring Without Repeating Characters
Category Kafka
가상 로그 데이터를 Streaming 처리해보기라는 목표를 가지고 지금까지 어떻게 구성했는지를 소개드리려고 합니다.
앞에서는 가상의 로그 데이터를 발생시켰습니다.
지금까지, 로그 데이터 구성하기를 진행하는 과정에 있어 Kafka, HDFS, Spark 클러스터를 구성하였습니다.
가상의 대용량의 로그 데이터를 만들어 Kafka → Hadoop에 저장해보려고 합니다.
Category Ec2
Pyspark로 연결 시도 시 datanode에 값이 없다고 한다.
Category Cluster
지금까지, 로그 데이터 구성하기를 진행하는 과정에 있어 Kafka, HDFS, Spark 클러스터를 구성하였습니다.
Pyspark로 연결 시도 시 datanode에 값이 없다고 한다.
Category Tableau
안녕하세요 오늘은 태블로 대시보드 슬랙 자동화하기를 해보려고 합니다.
Category RDBMS
정규화(Normalization)
💡 RDBMS에서 중복을 최소화 및 종속 관계의 속성을 제거하기 위한 프로세스
Category CloudWatch
요구 사항
만약, 내부 서비스에 대해 누가 사용한지 여부를 로깅하여 컨트롤하고 싶다면 어떻게 해야 할까?
Category Programmers
https://school.programmers.co.kr/learn/courses/30/lessons/42587
https://school.programmers.co.kr/learn/courses/30/lessons/42584
https://school.programmers.co.kr/learn/courses/30/lessons/42583
문제 : https://school.programmers.co.kr/learn/courses/30/lessons/42578
문제 : https://school.programmers.co.kr/learn/courses/30/lessons/42579
문제 : https://school.programmers.co.kr/learn/courses/30/lessons/42586#
Category Cache
안녕하세요.
오늘은 캐싱 전략에 대해 알아보려고 합니다.
Category Redis
안녕하세요.
오늘은 캐싱 전략에 대해 알아보려고 합니다.
Category Prometheus
안녕하세요.
그동안 감기와 차세대 업무로 인하여, 블로그 작성을 간만에 해봅니다.
Category Grafana
안녕하세요.
그동안 감기와 차세대 업무로 인하여, 블로그 작성을 간만에 해봅니다.
Category Mysql
Category Index
Category Kubernetes
Airflow를 다른 Executor를 활용해서 구성해보고 실행해보려고 합니다.
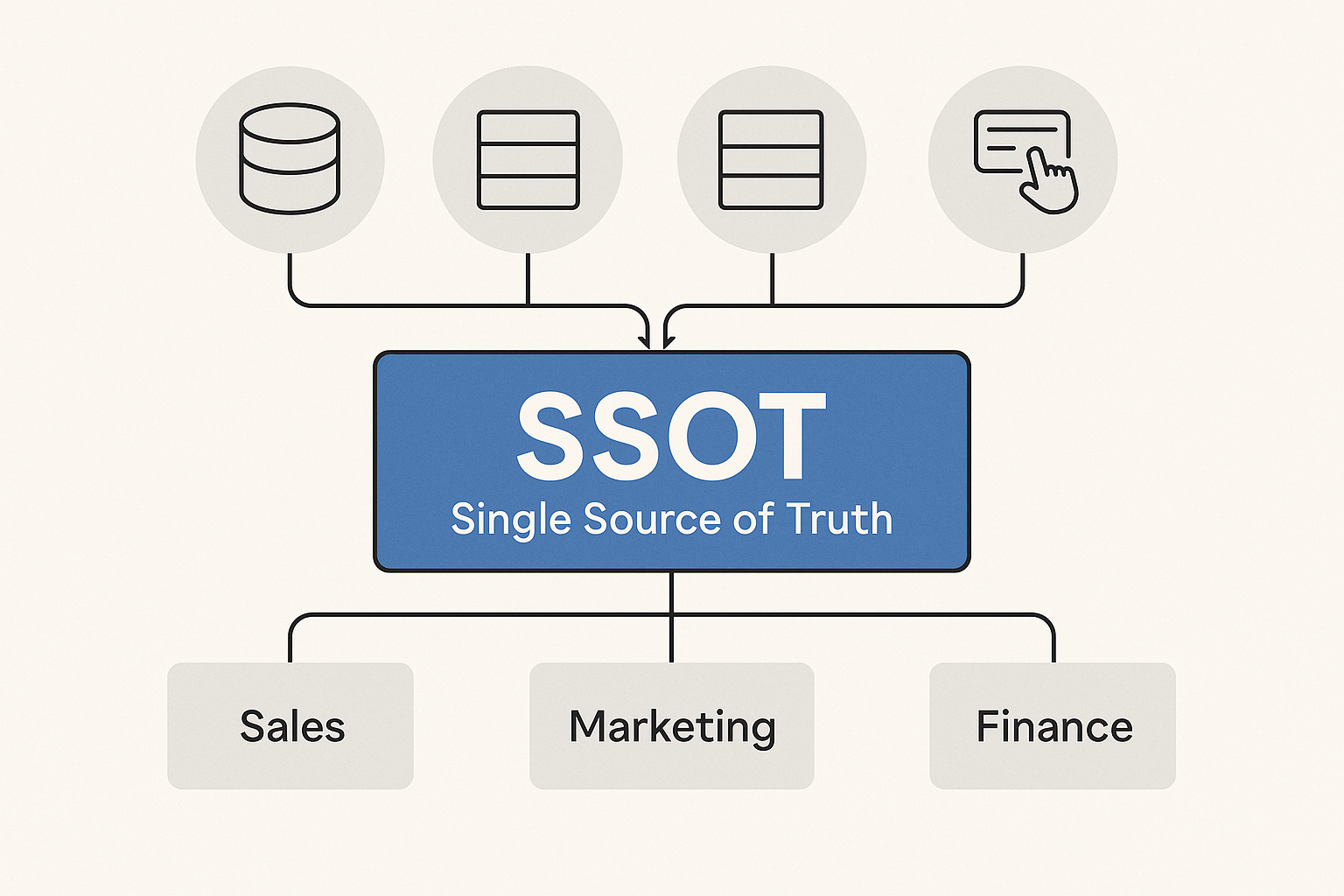
Category Data_Governance
SSOT 이상과 환상 그리고 지금까지 겪어온 경험을 이야기를 해볼까합니다.
Category DataLake
Athena 기반 환경에서 Apache Iceberg를 사용할 때, Timezone과 관련된 Timestamp 값이 의도와 다르게 처리되는 문제가 발생했습니다.
최근 빠르게 증가하는 데이터와 다변화된 데이터 소스에 따라 기존 S3 + Parquet 기반 DataLake의 구조만으로는 운영 효율성, 데이터 신뢰성에 한계가 있었습니다. 이글에서는 Apache Iceberg를 도입하게 된 배경과, 기존 환경에서 마주친...
Category Iceberg
Athena 기반 환경에서 Apache Iceberg를 사용할 때, Timezone과 관련된 Timestamp 값이 의도와 다르게 처리되는 문제가 발생했습니다.
최근 빠르게 증가하는 데이터와 다변화된 데이터 소스에 따라 기존 S3 + Parquet 기반 DataLake의 구조만으로는 운영 효율성, 데이터 신뢰성에 한계가 있었습니다. 이글에서는 Apache Iceberg를 도입하게 된 배경과, 기존 환경에서 마주친...



































![[RDBMS] 정규화&역정규화](/assets/images/rdbms.png)